Want to know more? — Subscribe
Today, we can find the best LLMs in many modern applications. They have become integral to search engines, virtual assistants, and even content generation. Google, OpenAI, and other companies have invested huge resources in developing top LLMs. These models drive advancements in conversational AI, machine translation, and academic research assistance.
LLMs can significantly boost human abilities and productivity in many areas as they get smarter. Yet, their broad and open-ended nature also raises challenges around bias and transparency that must be addressed. The capabilities of LLMs continue to grow at a tremendous pace. Overseeing their safe development is important to maximize their societal impact.
Softermii team explores what makes large language models unique and why they matter in today's tech world. This article contains an in-depth comparison of the ten most popular LLMs. Keep reading to get valuable advice on choosing the right model for your needs.

Understanding Large Language Models
LLMs lead in artificial intelligence, excelling in understanding and generating human-like text. They tackle tasks like summarizing, translating languages, and answering questions.
Discovering the essence of the best large language models involves breaking down what differentiates them from older language tools.

What are Large Language Models?
These deep neural networks learn from massive text data and catch statistical patterns and relationships in words, sentences, and paragraphs. The generative AI technology stack allows them to create relevant and fluent text.
LLM models function on a transformer architecture, processing sequential data alongside attention mechanisms. That contrasts earlier models like recurrent neural networks (RNNs) or convolutional neural networks (CNNs). Those two handled data with limited memory.
How do LLMs Differ from Traditional Language Processing Tools?
Traditional language processing tools rely on predefined rules or probabilities. They often need help with the intricacies of complex language.
In contrast, the top large language model offers flexibility and adaptability. Without explicit rules or labels, they learn dynamically from text data, navigating aspects like context, style, tone, emotion, and personality.
Unlike traditional tools that require human intervention and domain expertise, LLMs generate text that feels more natural and diverse.
Fine-tuning parameters or training on specific data subsets enables them to adapt to various tasks or domains quickly. That's a notable difference from the constraints of traditional language processing.
Top 10 Large Language Models
Numerous LLMs exist today, each with distinct strengths and weaknesses. All AI systems are proficient in generating natural language texts across diverse topics. Trained on extensive text data from multiple places, they capture the complexity of natural language patterns and structures.
While excelling in applications like question answering, text summarization, machine translation, and sentiment analysis, LLMs bring forth notable challenges. These include ethical, social, environmental, and technical considerations.
The leading ten LLMs are evaluated based on performance, scalability, efficiency, adaptability, and cost.
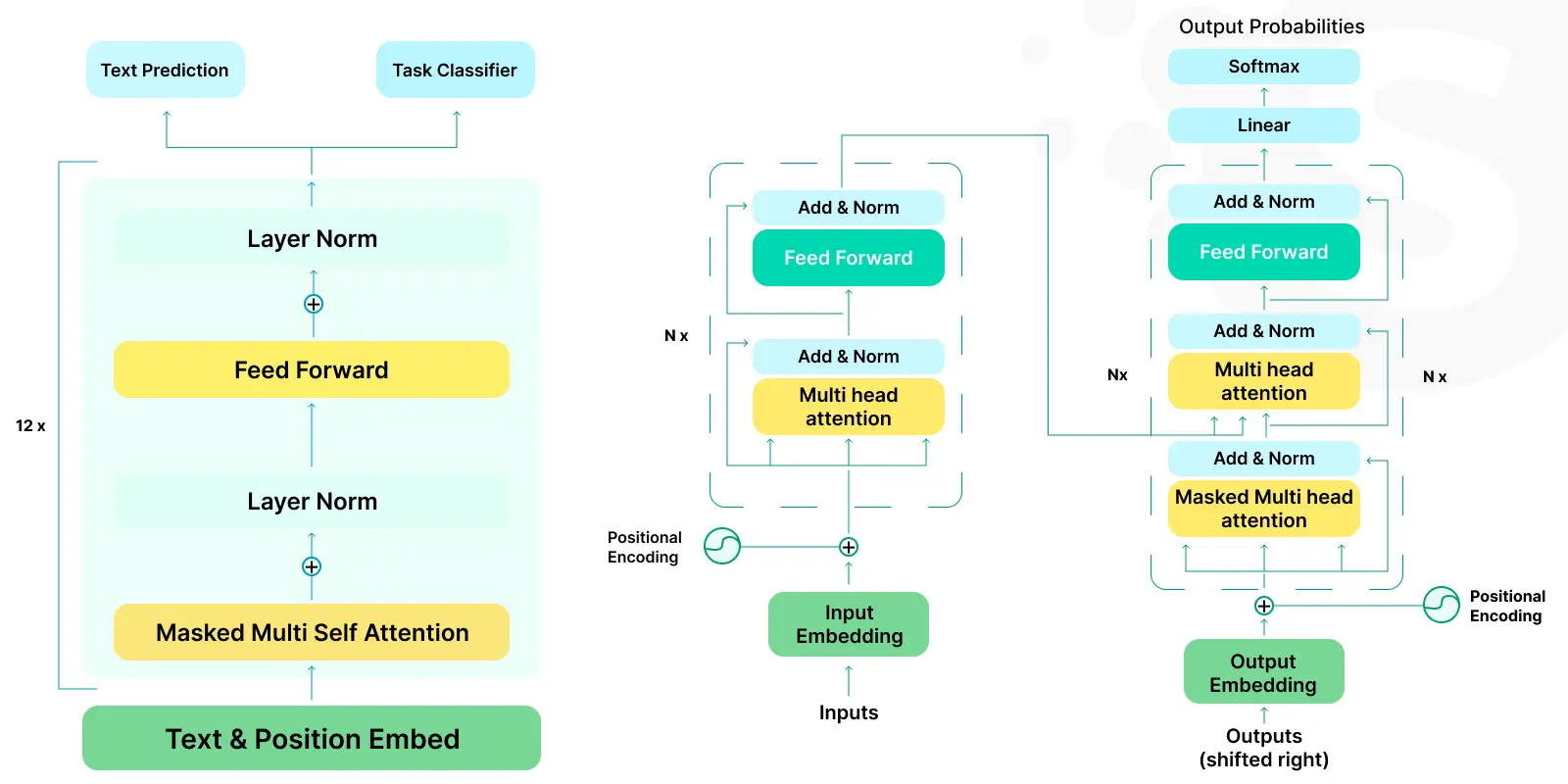
GPT-4 by OpenAI
GPT-4 is the latest iteration in OpenAI's Generative Pre-trained Transformer series. It's known for its advanced language understanding and generation capabilities. This open source LLM can produce human-like text across various topics and formats.
GPT-4 offers immense possibilities in content creation and customer service automation. It can assist with language translation and AI-driven educational tools. It's particularly suited for applications requiring creative and nuanced language processing. ChatGPT plugin development can adapt this model to various technological landscapes.
BERT by Google
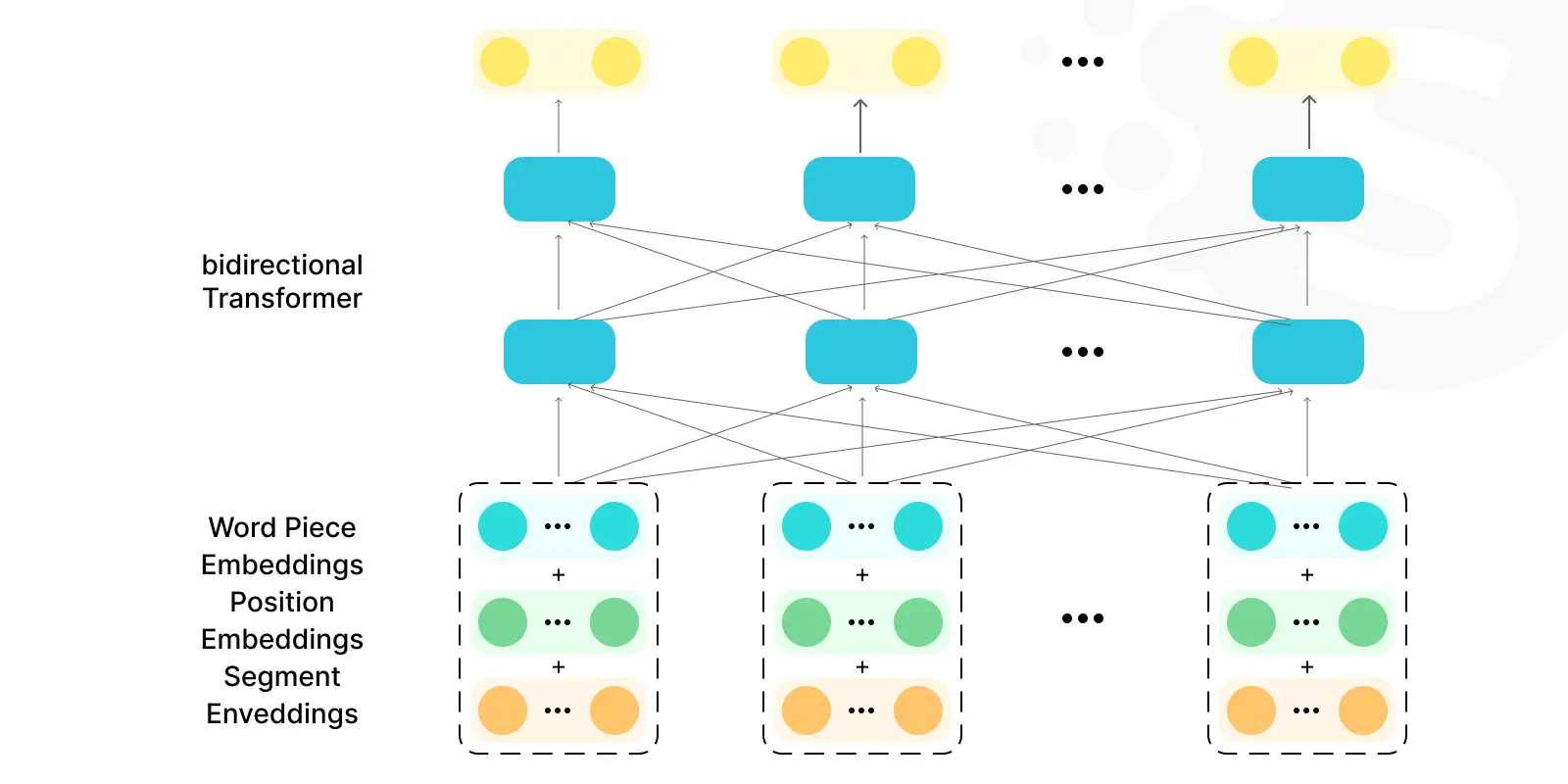
BERT represents a significant leap in the ability of machines to understand the nuances of human language. Its bidirectional training allows for a deeper understanding of the context.
BERT helps to enhance search engine results, sentiment analysis, and language translation services. It's ideal for tasks requiring understanding context and nuance in text.
T5 by Google
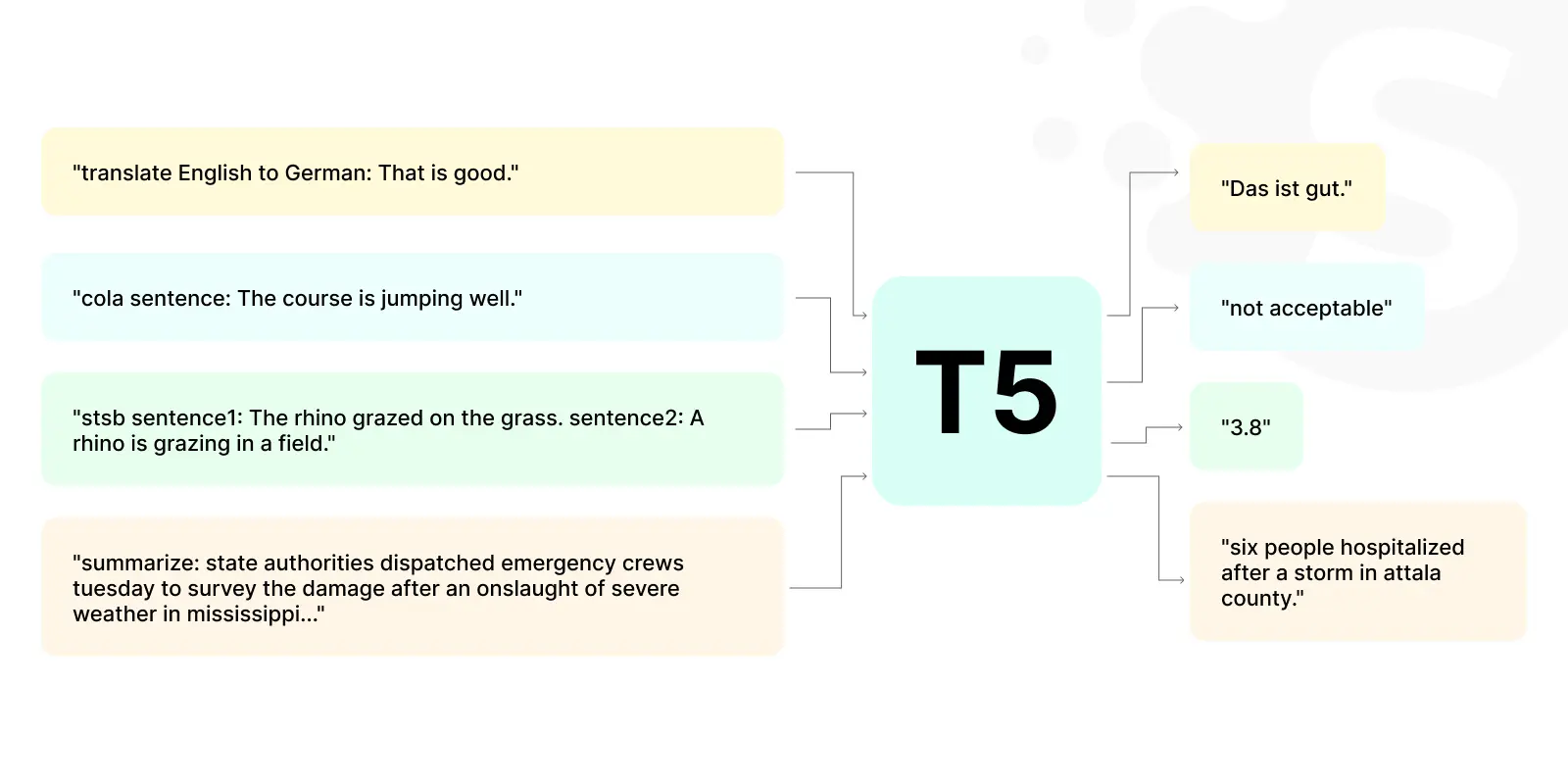
T5, or Text-To-Text Transfer Transformer, offers a unified framework for any NLP task presented as a text-to-text problem. With 11 billion parameters, it transforms input text into various desired outputs. It can provide questions, answers, summaries, translations, and paraphrases. T5 is a top LLM trained on the Colossal Clean Crawled Corpus (C4), comprising approximately 750 GB of web text data.
ERNIE by Baidu
ERNIE, or Enhanced Representation through Knowledge Integration, is a model adept at incorporating entities, relations, and concepts into its representations. With 12 billion parameters, it enhances performance in NLP tasks requiring semantic understanding — for example, entity linking, relation extraction, and knowledge graph completion. ERNIE is trained on Chinese Wikipedia, Baidu Baike, Baidu Tieba, and other Chinese text data sources, totaling around 16 GB.
ELECTRA by Google
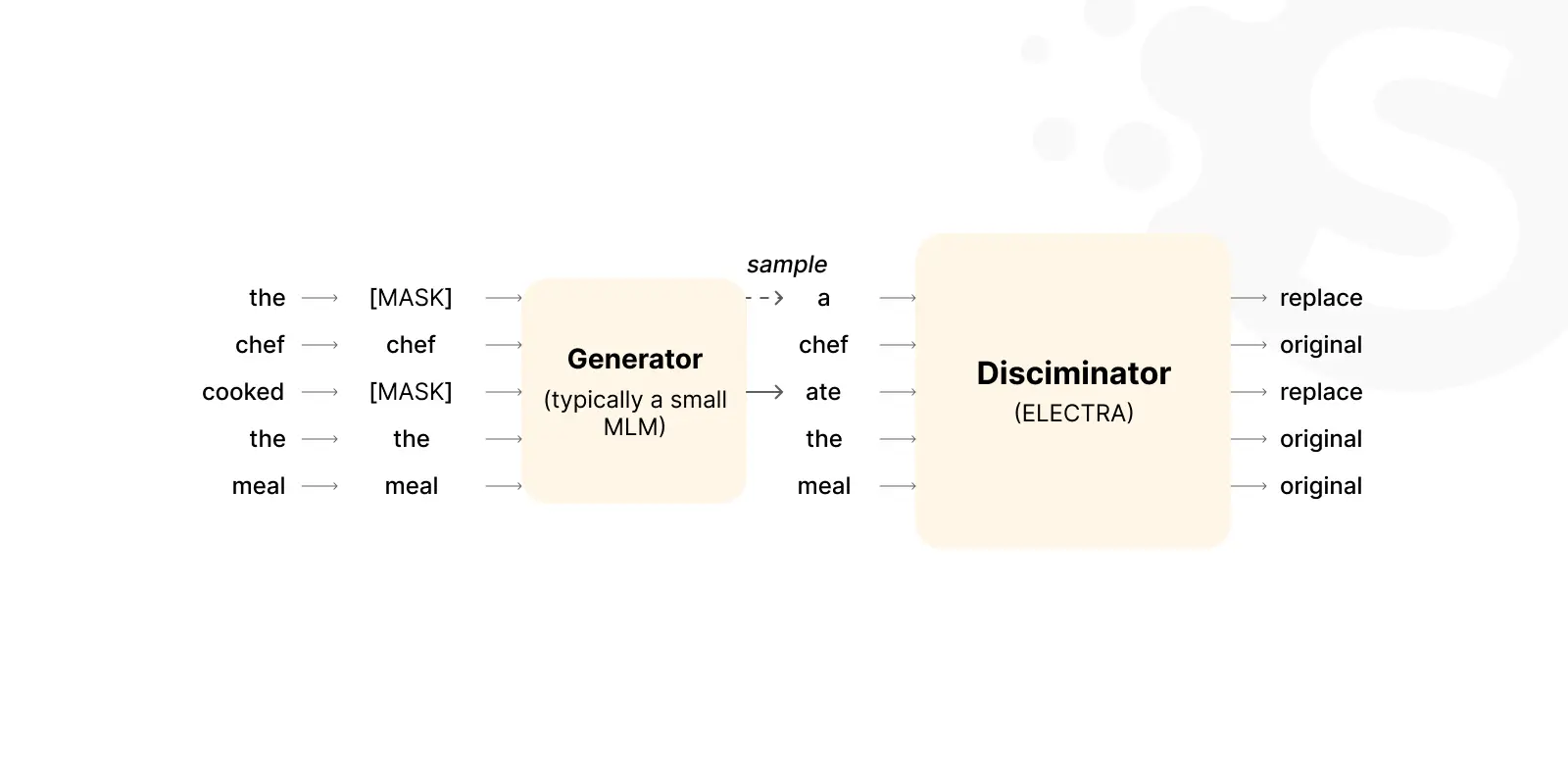
ELECTRA is another efficient learning framework by Google. It pre-trains text encoders and decoders by replacing tokens in a self-supervised learning task. With 699 million parameters, it learns from corrupted input texts. The model predicts whether each token is original or a replacement. Trained on the same datasets as BERT, ELECTRA is one of the best large language models that offer an innovative approach to self-supervised learning.
XLNet by Google/CMU
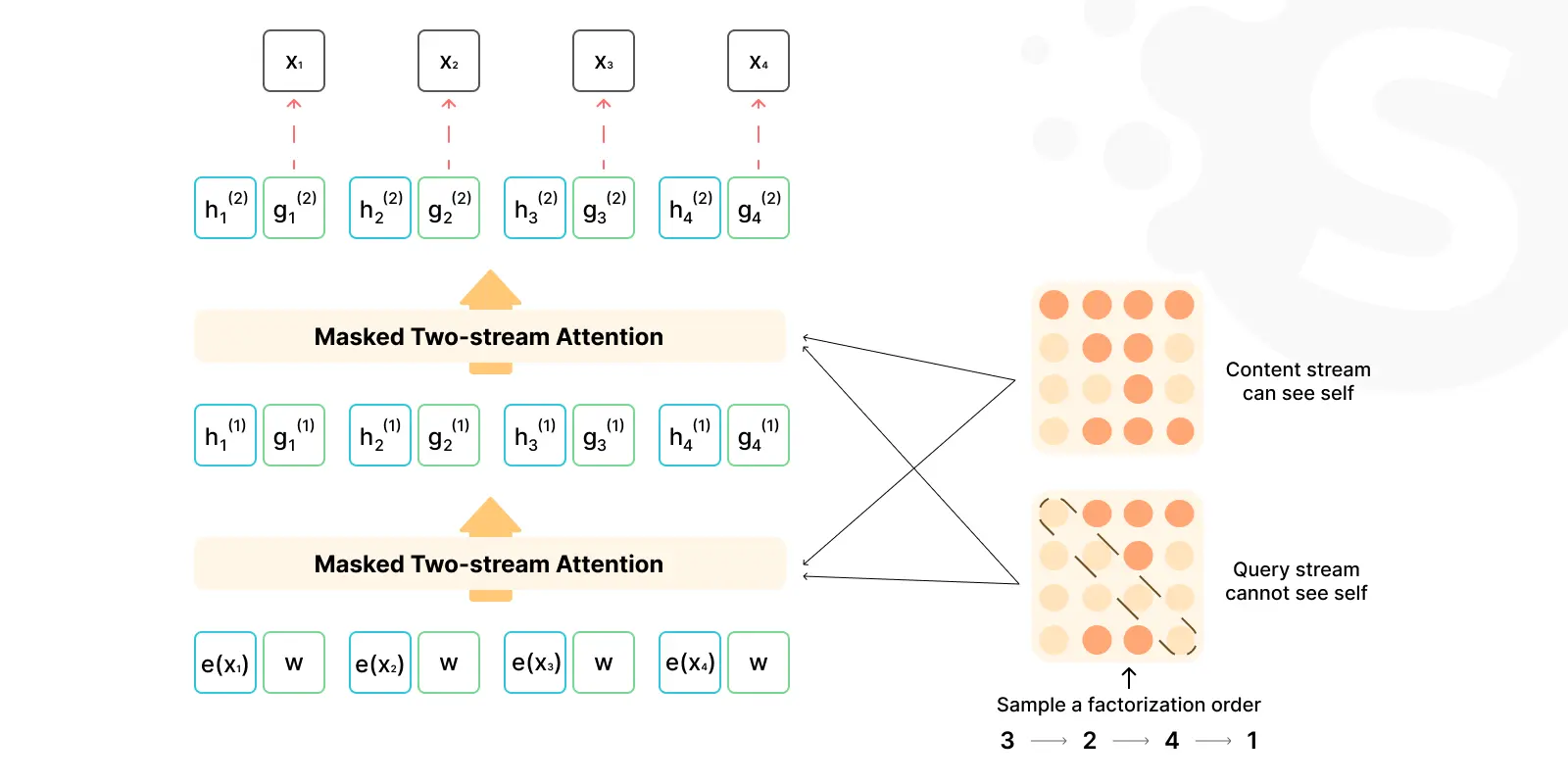
XLNet is a pre-training method developed by Google Brain and CMU. It's based on a permutation language modeling objective. It captures syntactic and semantic dependencies in natural language.
Its unique language modeling approach addresses the shortcomings of autoregressive and autoencoding methods. With 340 million parameters, XLNet is trained on datasets like BERT, offering a thorough grasp of language structures.
Megatron-LM by NVIDIA
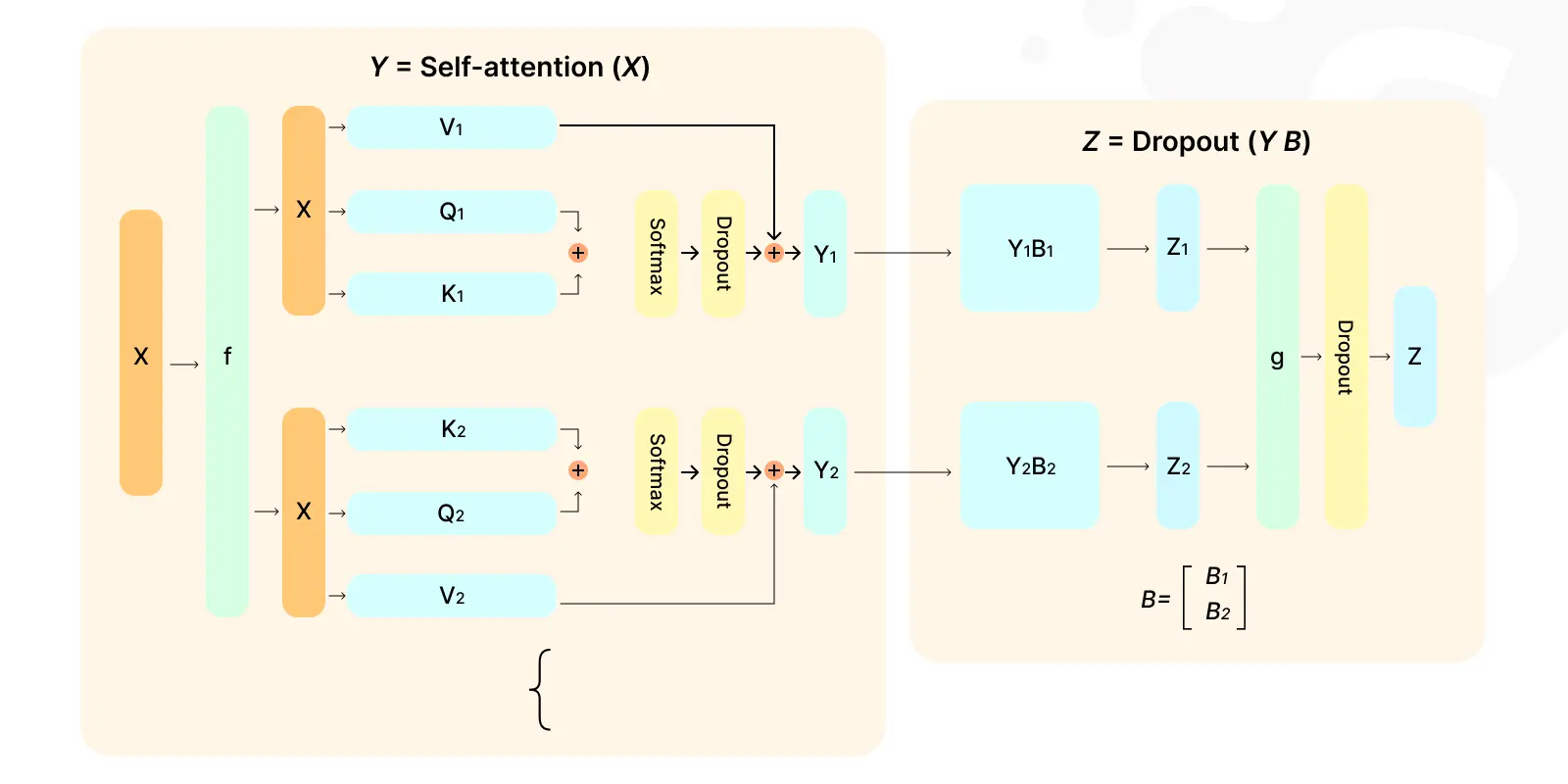
Designed for large-scale training, Megatron-LM is another powerful model on our best large language model list. It can process vast datasets, pushing the boundaries of language understanding and generation.
Its capabilities make it ideal for cutting-edge research and large-scale content generation. It is ideal for complex language modeling tasks, especially in academic and large enterprise settings.
LaMDA by Google
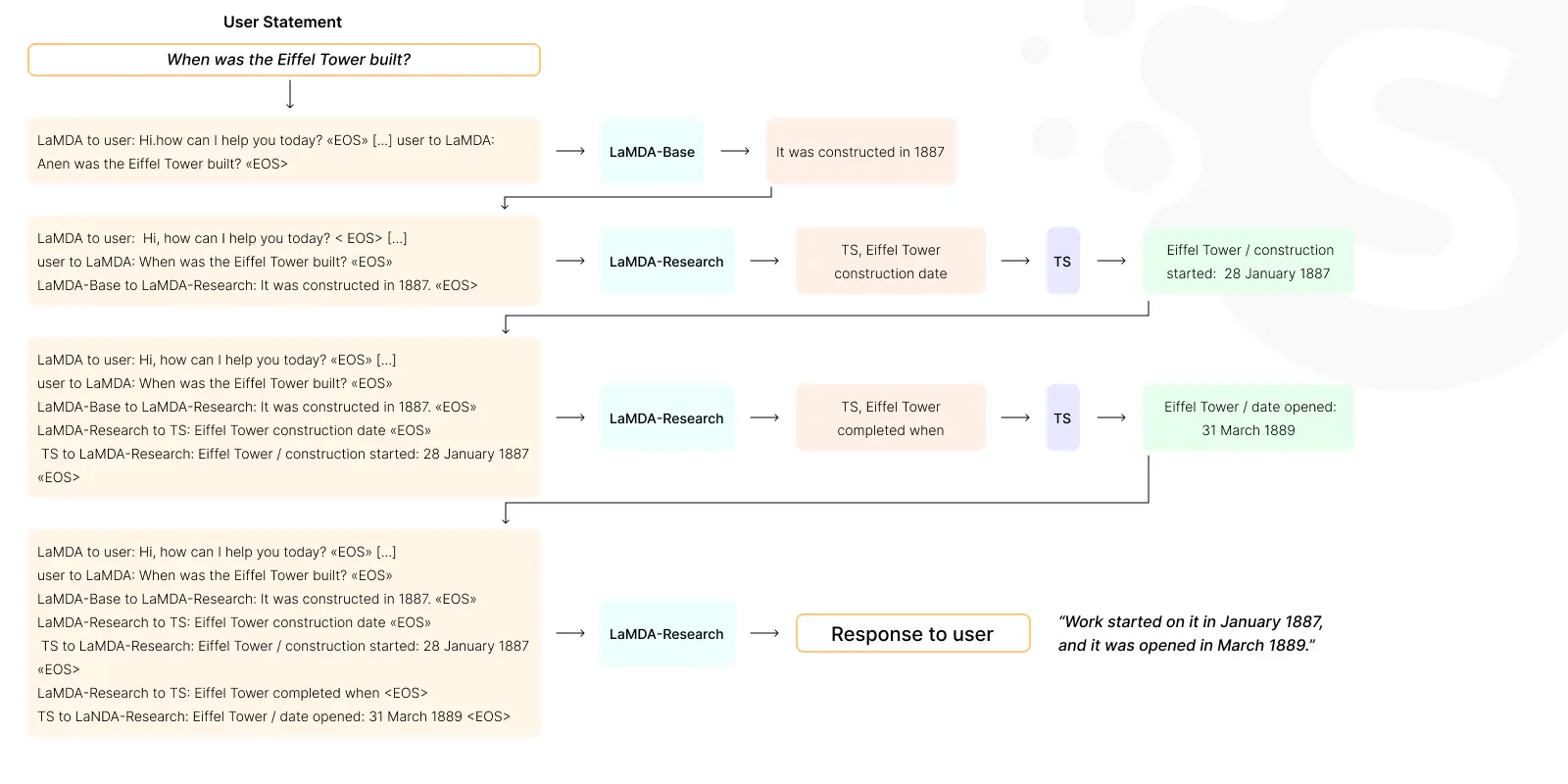
LaMDA (Language Model for Dialogue Applications) is specialized in conversational AI. It was designed to maintain more natural and open-ended conversations.
LaMDA opens doors in customer service chatbots, interactive storytelling, and virtual assistant technologies. The model offers a more engaging and human-like conversational experience.
RoBERTa by Facebook
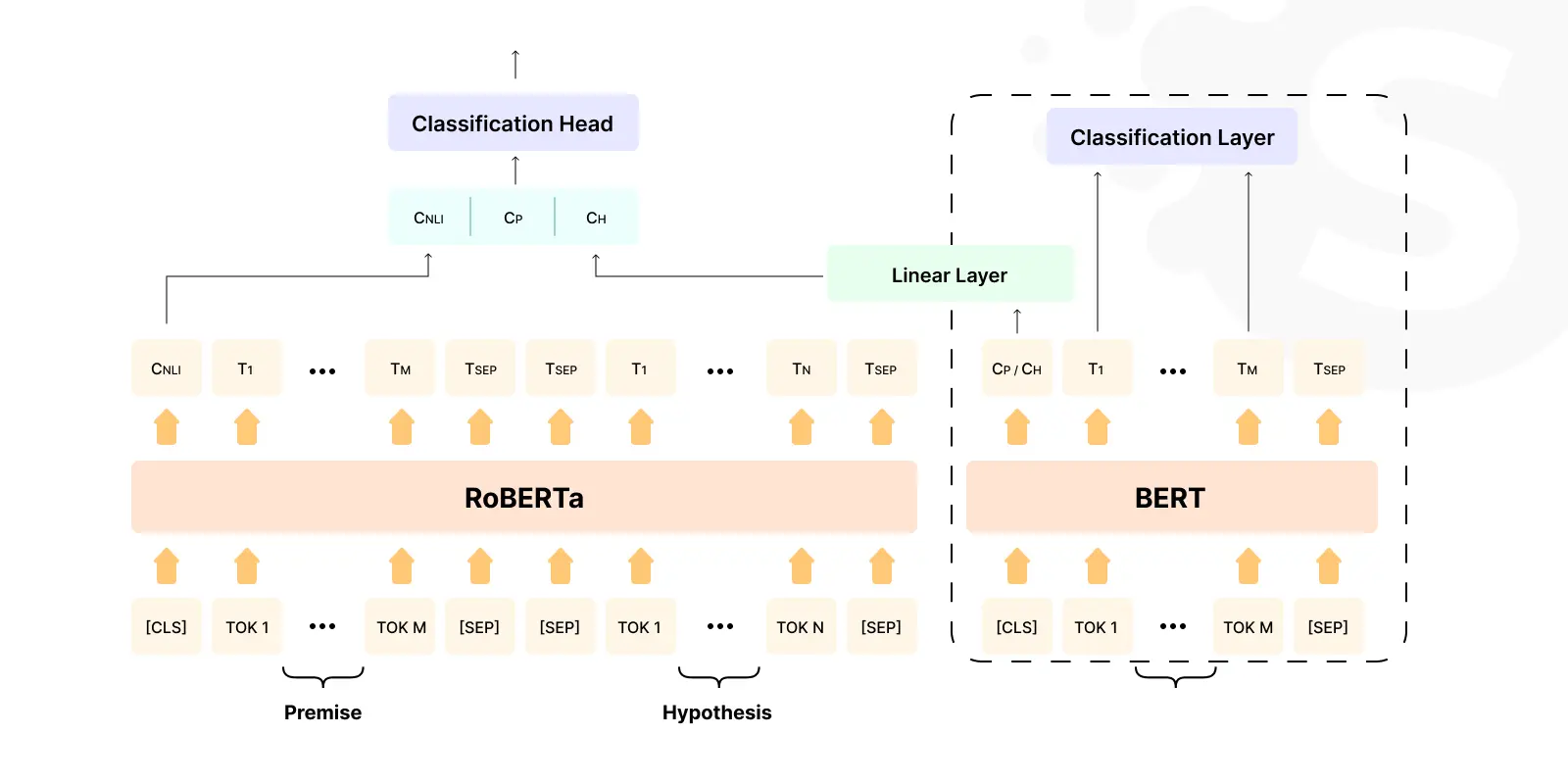
As the name suggests, RoBERTa is an optimized version of BERT. It has better performance by training on more data and with longer sequences.
The model is particularly effective in tasks requiring deep linguistic insights such as:
- sentiment analysis;
- language inference;
- content moderation.
Jurassic-2 by AI21 Labs
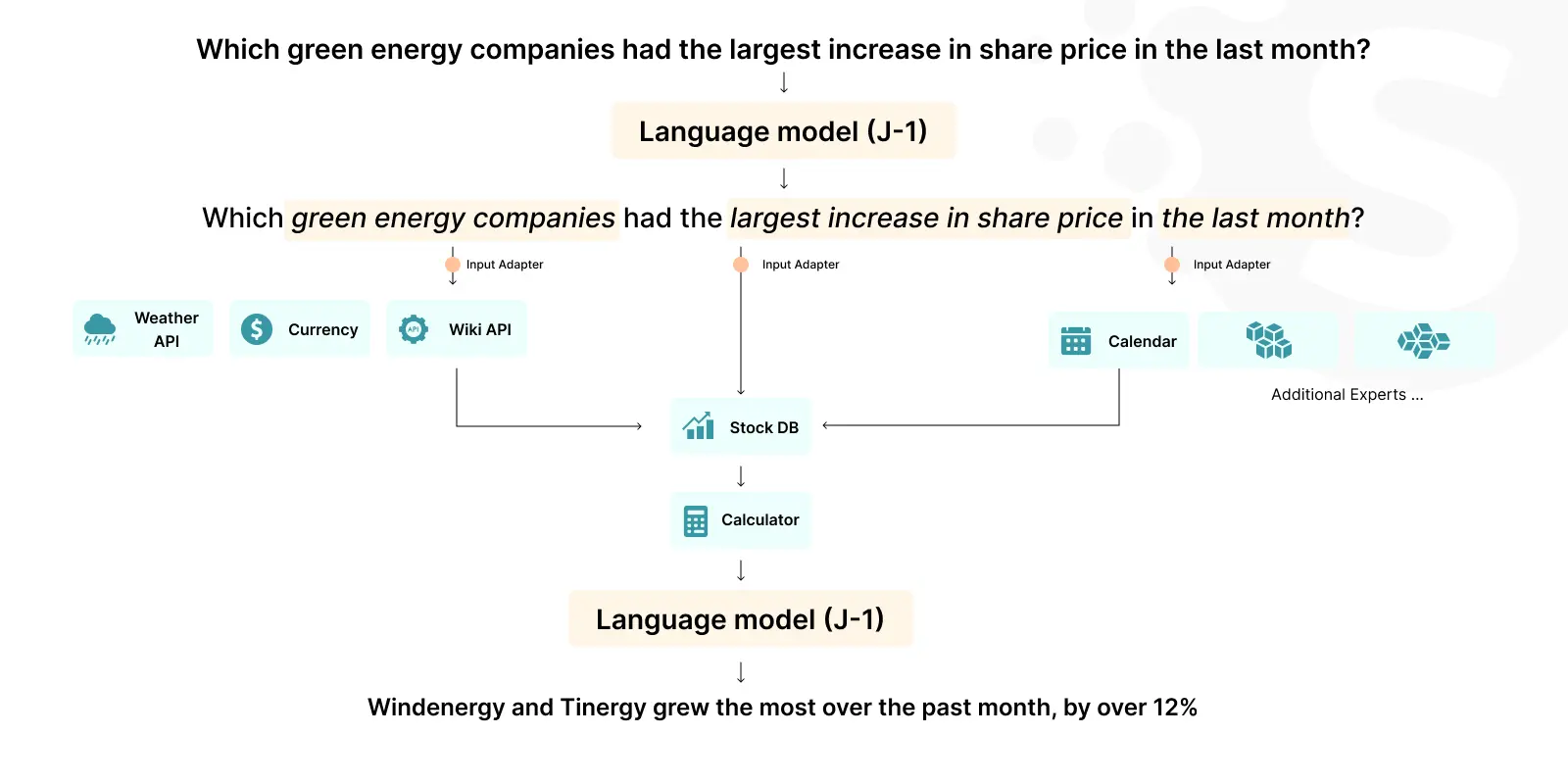
Jurassic-2 stands out for its ability to be customized for specific tasks. It offers a balance between general-purpose language understanding and specialized applications.
Its customizability makes it suitable for diverse applications, from creating tailored chatbots to specialized content generation. Jurassic-2 caters to businesses seeking a more tailored approach to NLP.
How to Choose the Best Large Language Model
Choosing the best large language model for your application can be challenging. This choice involves considering various factors, including the following:
- Performance and Accuracy. How each model performs in various language tasks and their accuracy levels.
- Scalability. How well the LLM can be expanded and adapted to larger datasets and more complex tasks.
- Efficiency. The energy consumption and processing power requirements of each model.
- Adaptability and Learning. How each model handles new data and its learning algorithms' effectiveness.
- Cost and Affordability. An overview of the required financial investments, considering model capabilities and resource needs.
Below is a comparison table highlighting key aspects of the top 10 LLMs. They help to select the right model for complex data analysis, content generation, or specialized tasks.
|
Model |
Performance and Accuracy |
Scalability |
Efficiency |
Adaptability and Learning |
Cost and Affordability |
|---|---|---|---|---|---|
|
GPT-4 |
High accuracy and versatility in diverse topics, with occasional inaccuracies in niche subjects. |
Highly scalable but requires large computational resources. |
Energy-intensive due to large model size. |
Rapid adaptation to new data; excellent learning capabilities. |
High cost, particularly for commercial applications. |
|
BERT |
Context-aware word representations. Excels in sentiment analysis and QA. |
Scalable but requires fine-tuning for each task. |
Moderately efficient. Fine-tuning can be resource-intensive. |
Good adaptability; needs task-specific training. |
Cost-effective for smaller-scale applications. |
|
T5 |
Unified text-to-text approach. Versatile, but may lack nuance in specialized tasks. |
Scalable across a range of tasks. |
Efficient in handling multiple tasks with one model. |
Adapts well to new data; versatile learning. |
Medium to high cost, depending on usage scale. |
|
ERNIE |
Superior in Chinese language tasks, less effective in others. |
Scalable, particularly in Chinese language applications. |
Energy efficiency varies with task complexity. |
Good learning with enhanced semantic understanding. |
Cost-effective, especially for Chinese language applications. |
|
ELECTRA |
Efficient in learning; may not match the depth of contextual understanding as others. |
Scalable, particularly for tasks requiring less contextual depth. |
More energy-efficient than larger models. |
Quick to adapt and learn, but may need fine-tuning. |
Generally cost-effective. |
|
XLNet |
Outperforms BERT in text completion and complex training. |
Highly scalable, but complexity can be a barrier. |
Less efficient due to training complexity. |
Strong learning algorithm; excels in bidirectional understanding. |
Costs can escalate due to training requirements. |
|
Megatron-LM |
Efficient in processing large datasets, requires significant resources. |
Extremely scalable for large datasets. |
High computational resource requirements. |
Rapid learning capabilities, especially with large data. |
High cost due to computational demands. |
|
LaMDA |
Specialized in dialogues; may lack versatility. |
Scalable in conversational AI applications. |
Efficiency varies depending on conversation complexity. |
Excellent in adapting to conversational contexts. |
Cost varies, potentially high for advanced applications. |
|
RoBERTa |
Improved accuracy in language understanding over BERT. |
Scalable; similar to BERT but with added resource needs. |
Resource-intensive, similar to BERT. |
Adapts well but requires extensive training data. |
Moderate to high cost. |
|
Jurassic-2 |
Customizable and effective in e-commerce applications. |
Scalable and adaptable to various tasks. |
Efficiency depends on customization and task. |
Strong in task-specific learning and adaptation. |
Cost varies based on customization and scale of use. |
|
|
|||||
We acknowledge that navigating through this comparison table may feel overwhelming. To simplify the process, here are the best LLM insights:
Performance and Accuracy
GPT-4, BERT, and T5 are leaders in performance and accuracy. GPT-4 is known for its human-like text generation and versatility. BERT excels in context-aware processing, particularly beneficial in nuanced language understanding. T5's unified text-to-text approach makes it efficient in diverse tasks. However, it may have limitations in more specialized tasks.
Models like ERNIE and RoBERTa have specific strengths, such as:
- ERNIE's enhanced semantic understanding in Chinese;
- RoBERTa's improved accuracy over BERT.
Scalability
Megatron-LM and XLNet are remarkable for their scalability, especially in handling large datasets and complex models. Yet, this comes with higher resource demands.
GPT-4 and T5 also offer good scalability but require significant computational resources. They are more suitable for organizations with the necessary infrastructure.

Efficiency
ELECTRA stands out for its training efficiency. It uses a novel pre-training approach that enhances learning speed.
Thanks to its versatile text-to-text framework, T5 offers a good balance in efficiency across tasks.
Adaptability and Learning
GPT-4 and T5 can handle a wide range of tasks with high competency. Their learning algorithms allow them to adapt to new data and tasks rapidly.
ERNIE, with its focus on semantic understanding, demonstrates strong adaptability in language tasks. It is particularly evident in its native Chinese language context.
Cost and Affordability
High-end models like GPT-4 and XLNet entail bigger costs due to their advanced capabilities and resource requirements.
Models like ELECTRA and ERNIE balance performance with resource efficiency. Thus, they might offer more cost-effective solutions for specific applications.
Conclusion
LLMs have made impressive strides over the past few years and show the power of self-supervised learning. Each of the discussed models brings unique strengths and considerations. But we've only started exploring the possibilities that come with increased computational capabilities and data. LLMs get larger, more versatile, and human-like in their abilities. This way, they blend into the background of our technologies and interactions.
Choosing the right LLM for your business requires careful consideration of various factors. You should choose the right blend of performance, scalability, efficiency, adaptability, and cost. Softermii can help you with personalized guidance and assistance selecting the most suitable LLM. Contact us to build the future of language interfaces with technology.
Frequently Asked Questions
What is the most powerful LLM?
The term "most powerful" can vary based on the specific application and requirements. GPT-4 and XLNet are often considered among the most powerful models due to their size and broad capabilities. But, for certain tasks, Google's BERT, Claude, or NVIDIA's Megatron-LM might be more effective.
Is GPT-4 the best LLM?
GPT-4 is known for its advanced capabilities in generating human-like text. It also has great versatility across a wide range of tasks. But, whether it is the "best" LLM depends on the particular context and requirements of the project. For example, BERT might be better for understanding the context of search queries. T5 can be a top choice for tasks requiring a unified text-to-text approach. Additionally, for those looking to create a ChatGPT chatbot, leveraging GPT -4's capabilities can offer a sophisticated and human-like conversational experience.
What are the most popular LLMs?
The most popular LLMs are GPT-4 by OpenAI, BERT and T5 by Google, and RoBERTa by Facebook. Each of them has gained popularity for unique strengths in language processing tasks.
How are large language models fine-tuned?
Large language models are fine-tuned by training them on a dataset relevant to the specific task. Scientists adjust the model's weights to align with project nuances and requirements. Thus, they improve LLM's performance in specific applications like sentiment analysis, code generation, or domain-specific information retrieval.
What role does Google play in the development of LLMs?
Google has been a key player in the development of LLMs. They have developed several influential models like BERT, T5, and LaMDA. Google's contribution lies in:
- pioneering research in natural language processing;
- developing new methodologies (like the transformer architecture).
The company pushes the boundaries of what LLMs can achieve. They have greatly contributed to the progress in data science and machine learning technologies.
How about to rate this article?





0 ratings • Avg 0 / 5
Written by: